Zależało mi ostatnio na odpaleniu w pełni prywatnego asystenta. Chciałem mieć swój lokalny LLM, żeby móc swobodnie testować polecenia, analizować logi i bawić się skryptami bez wysyłania jakichkolwiek zapytań na zewnętrzne serwery. Padło na CachyOS – rewelacyjnie zoptymalizowanego Linuxa, którego akurat miałem zainstalowanego na jednym z pobocznych sprzętów. Wydawało się, że to będzie szybka akcja, ale specyfikacja maszyny szybko zweryfikowała moje plany. Komputer testowy miał zaledwie 8 GB RAM.
Zacznijmy jednak od początku. Najlepszym środowiskiem do zarządzania lokalnymi modelami jest aktualnie Ollama. Działa jako cicha usługa w tle, nie obciąża niepotrzebnie procesora, a nowe modele pobiera się z terminala tak łatwo, jak pakiety z repozytorium.
Instalacja Ollamy na CachyOS
Ponieważ ten system mocno bazuje na Archu, instalacja to dosłownie kilka sekund. Odpaliłem terminal i wpisałem standardową komendę:


sudo pacman -S ollama
Następnie trzeba uruchomić samą usługę, aby działała od razu i automatycznie podnosiła się przy każdym restarcie komputera:
sudo systemctl enable --now ollama
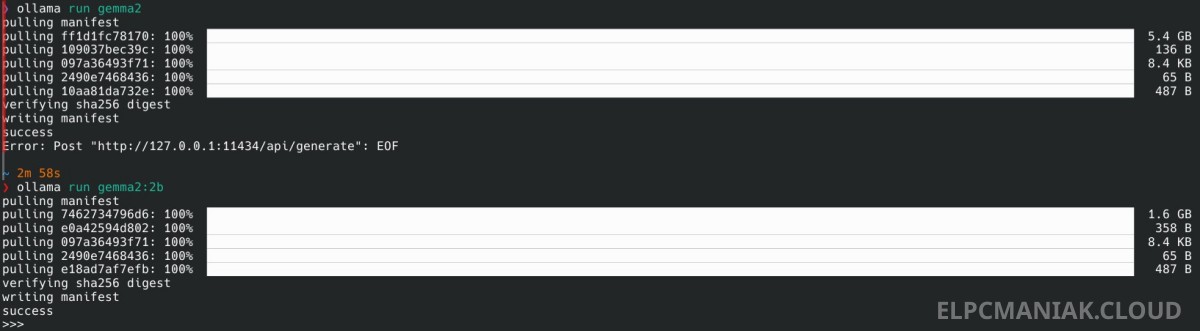
Do tego momentu szło niezwykle gładko. Zdecydowałem się przetestować świetny model od Google. Wklepałem więc polecenie ollama run gemma2 i poszedłem zrobić kawę, czekając na pobranie plików.
Zderzenie ze ścianą: Błąd EOF
Po chwili konsola dociągnęła 5.4 GB danych. Pasek doszedł do 100%, weryfikacja sum kontrolnych minęła bezbłędnie i nagle moim oczom ukazał się komunikat:
Error: Post "http://127.0.0.1:11434/api/generate": EOF.
Zajrzałem do logów systemowych i sprawa od razu stała się jasna. Zabrakło pamięci operacyjnej. Domyślna wersja Gemma 2 (w architekturze 9B) waży swoje na dysku, ale po wczytaniu do RAM-u oraz zarezerwowaniu miejsca na tzw. kontekst rozmowy, potrzebuje łącznie około 8-9 GB wolnej przestrzeni. Mój system awaryjnie ubił proces Ollamy (zadziałał tzw. mechanizm OOM Killer), żeby nie zawiesić całego środowiska graficznego.
Rozwiązanie dla 8 GB RAM
Jeżeli dysponujecie starszym sprzętem, nie oznacza to wcale końca zabawy z prywatną sztuczną inteligencją. Zamiast dużej wersji, wystarczy pobrać wariant z mniejszą liczbą parametrów.
Wklepałem po prostu:
ollama run gemma2:2b
Ta wersja waży zaledwie 1.6 GB. Została załadowana do pamięci błyskawicznie. Na ekranie pojawił się wyczekiwany znak zachęty >>> i mogłem normalnie zacząć pracę z asystentem. Generowanie tekstu jest płynne, a system operacyjny zupełnie nie dusi się z braku wolnych zasobów.
Może Cię zainteresować: Jak uruchamiać gry z Windows na Linux Mint?
Co w sytuacji, gdy masz mocniejszy sprzęt?
Z drugiej strony, jeżeli Twój główny komputer posiada 16 GB, 32 GB RAM lub dysponujesz dedykowaną kartą graficzną z solidną dawką VRAM, możesz całkowicie zignorować moje przeboje z brakiem pamięci. Wtedy zdecydowanie warto celować w pełną wersję.
Wpisujesz w terminalu podstawowe:
ollama run gemma2
Ollama jest na tyle sprytna, że sama wykryje dostępne w systemie zasoby, przerzuci najcięższe obliczenia na kartę graficzną i odda w Twoje ręce niezwykle potężnego asystenta.
Wybór lokalnego modelu AI: Gemma 2, Llama 3.2 czy Phi-3?
Skoro usługa już działa, pojawia się kluczowe pytanie – jaki lokalny LLM pobrać? Zawsze lubiłem wiedzieć, jaki silnik pracuje pod maską, dlatego przetestowałem kilka najpopularniejszych rozwiązań. Społeczność open-source rozwija się niezwykle dynamicznie, a my mamy do dyspozycji co najmniej trzy świetne opcje, które idealnie pasują na domowy serwer czy starszy komputer z 8 GB RAM. Różnią się one jednak swoimi predyspozycjami.
Gemma 2 (od Google)
To właśnie ten silnik opisywałem wyżej. Wersja 2B (około 1.6 GB) to kapitalny kompromis między wydajnością a niskim zużyciem zasobów. Bardzo dobrze radzi sobie z ogólnymi odpowiedziami i logiką. Z kolei wersja 9B to znacznie wyższy poziom rozumowania, ale jak już boleśnie udowodniłem, bez 16 GB RAM i solidnej karty graficznej system operacyjny szybko zaprotestuje.
Llama 3.2 (od Meta)
Obecnie to jeden z najchętniej pobieranych modeli sztucznej inteligencji. Wariant 3B zajmuje zaledwie około 2 gigabajtów na dysku i bez zająknięcia ładuje się do mniejszej pamięci operacyjnej. Zauważyłem, że Llama świetnie radzi sobie z luźniejszymi, codziennymi zadaniami, kategoryzowaniem danych czy generowaniem kreatywnych rozwiązań. Działa bardzo płynnie, nie obciążając zbytnio procesora.
Phi-3 Mini (od Microsoftu)
Moje małe odkrycie do zadań czysto technicznych. Mimo bardzo skromnych rozmiarów (niecałe 2.4 GB), Phi-3 został wytrenowany z ogromnym naciskiem na jakość danych, a nie ich ilość. Jeżeli potrzebuję na szybko przeanalizować skomplikowane logi błędów z serwera, sprawdzić konfigurację firewalla albo napisać sprytny skrypt w bashu do automatyzacji backupów, Phi-3 często wyciąga lepsze wnioski niż więksi konkurenci.
Wielkim plusem Ollamy jest to, że nie musisz ograniczać się do jednego rozwiązania. Możesz pobrać je wszystkie i płynnie przełączać się między nimi, po prostu zmieniając nazwę po komendzie ollama run.
Powyższy eksperyment udowadnia jedno: uruchomienie sztucznej inteligencji bezpośrednio na własnym dysku to już nie jest domena potężnych klastrów serwerowych, a kwestia wpisania trzech komend. Zatem zdecydowanie warto poświęcić chwilę i przetestować to u siebie.